API 서버 학습 : 모니터링

왜 모니터링이 필요했나요?
서비스를 개발중, 보다 면밀한 병목지점 파악 및 가시성을 위해 모니터링이 필요하다고 느꼈다.
캐시를 적용했지만, 여전히 커넥션풀 타임아웃이 발생해서 성능이나 요청 패턴을 실시간으로 확인할 필요가 있다.
또한, 추가적으로 성능 개선을 할 부분들을 하나씩 짚고 넘어가기에 좋다고 생각했다. 기존에 했던 코드 개선 & 캐싱은 워낙 직관적인 문제였기에 바로 적용이 가능했지만, 이후부터는 병목/문제 지점을 정확히 찾아야 한다.
이 과정에서, Prometheus + Grafana 스택을 사용해서 측정하기로 했으나, 의존성이 늘어나서 관리하기 어려움을 느꼈으며, 추후 배포시점에도 관리가 피곤할 요소가 다분했기에, Docker & Docker Compose를 사용해서 컨테이너화 하는 것이 적절하다고 판단, 도입했다.
Prometheus
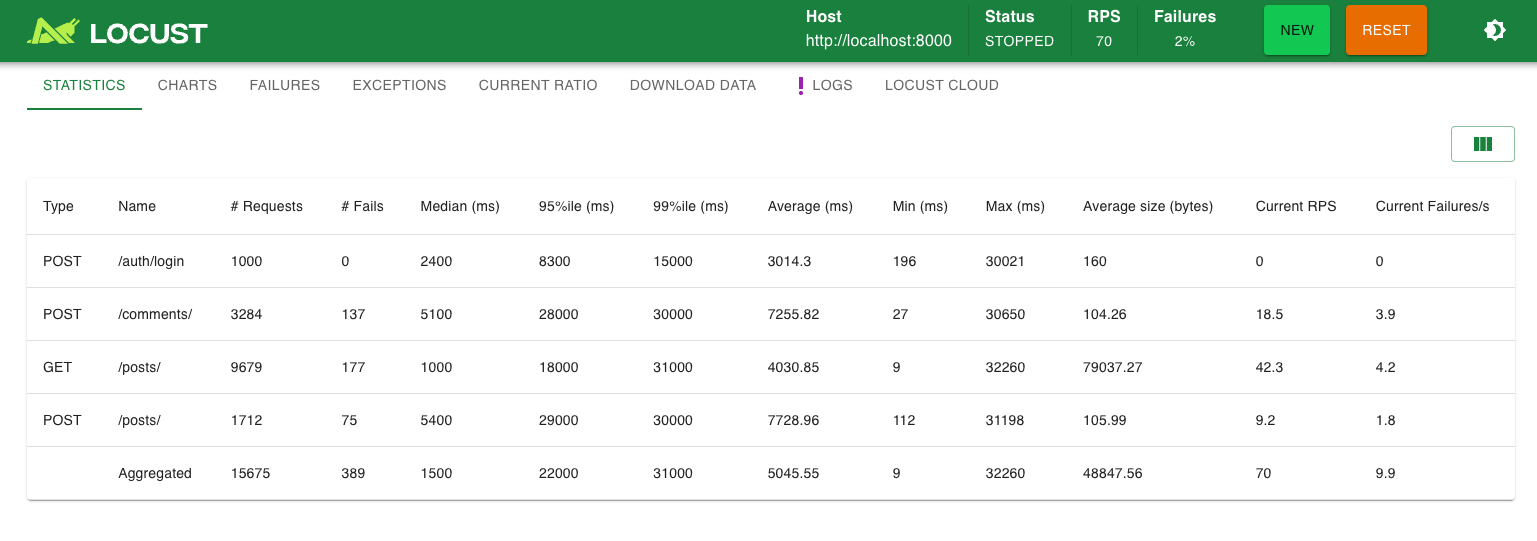
프로메테우스 추가 후 다시 한 번 clean db (기존과 동일 환경)에서 부하 테스팅을 돌렸는데, 전보다는 성능이 나아졌다. 프로메테우스가 성능을 개선한 것은 아닐테고, 랜덤성의 요소가 있기 때문에 그런 듯 하다. 일정 오차범위는 있지만, 여전히 실패는 발생하고 이는 동일하게 timeout 문제이다. 당장 커넥션 풀을 50개로 늘리는 방법도 생각해볼 수 있겠지만 최대한 20개를 유지하는 선에서 해보고 싶다.
기본으로 확인 가능한 http 요청에 더해 캐싱 비율을 확인하고자 redis의 get/set메서드에 대한 wrapper함수를 만들어 추가헀다.
1
2
3
4
5
6
7
8
9
10
11
async def cached_get(key: str):
value = await redis.get(key)
if value is None:
redis_misses.inc()
else:
redis_hits.inc()
return value
async def cached_set(key: str, value: str, ttl: int):
await redis.set(key, value, ex=ttl)
또한, 이제 관리해야 하는 것이 API 서버, Redis, Prometheus, Grafana 등이 있기에 이들을 하나씩 수동으로 껐다 키는 것은 비효율적이라고 판단하여 Docker-Compose로 관리하도록 했다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
services:
fastapi:
build: .
container_name: fastapi_app
ports:
- "8000:8000"
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
MYSQL_HOST: host.docker.internal
MYSQL_PORT: 3306
MYSQL_USER: root
MYSQL_PASSWORD: password
MYSQL_DB: fastapi
redis:
image: redis:7
container_name: redis
ports:
- "6379:6379"
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
ports:
- "9100:9100"
restart: unless-stopped
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- prometheus
Prometheus 적용 후 정상 적동하는지 확인하기 위해 redis_cache_hits_total을 먼저 확인해봤다:
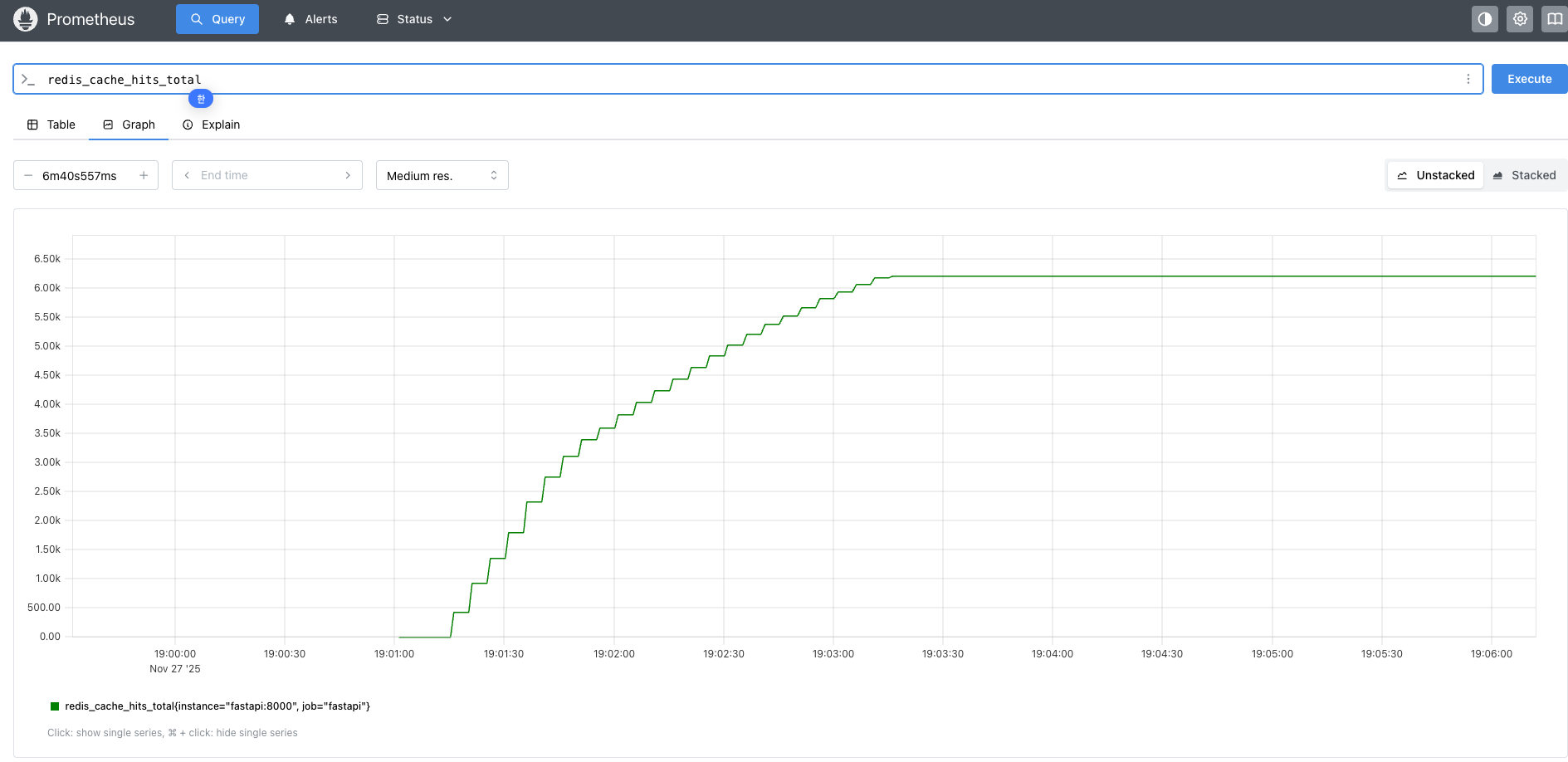
측정 지표
다음을 측정하고자 했다.
Redis hit ratio
1
redis_cache_hits_total / (redis_cache_hits_total + redis_cache_misses_total)
캐시 히트 비율을 먼저 확인하고자 했다.
현재 구현된 시스템은 GET /posts 와 POST /posts가 5:1 비율로 요청되는데, 완벽하게 이상적으로 POST - GET - GET - GET - GET - GET 순으로 동작한다면 히트율이 80%가 나와야 한다.
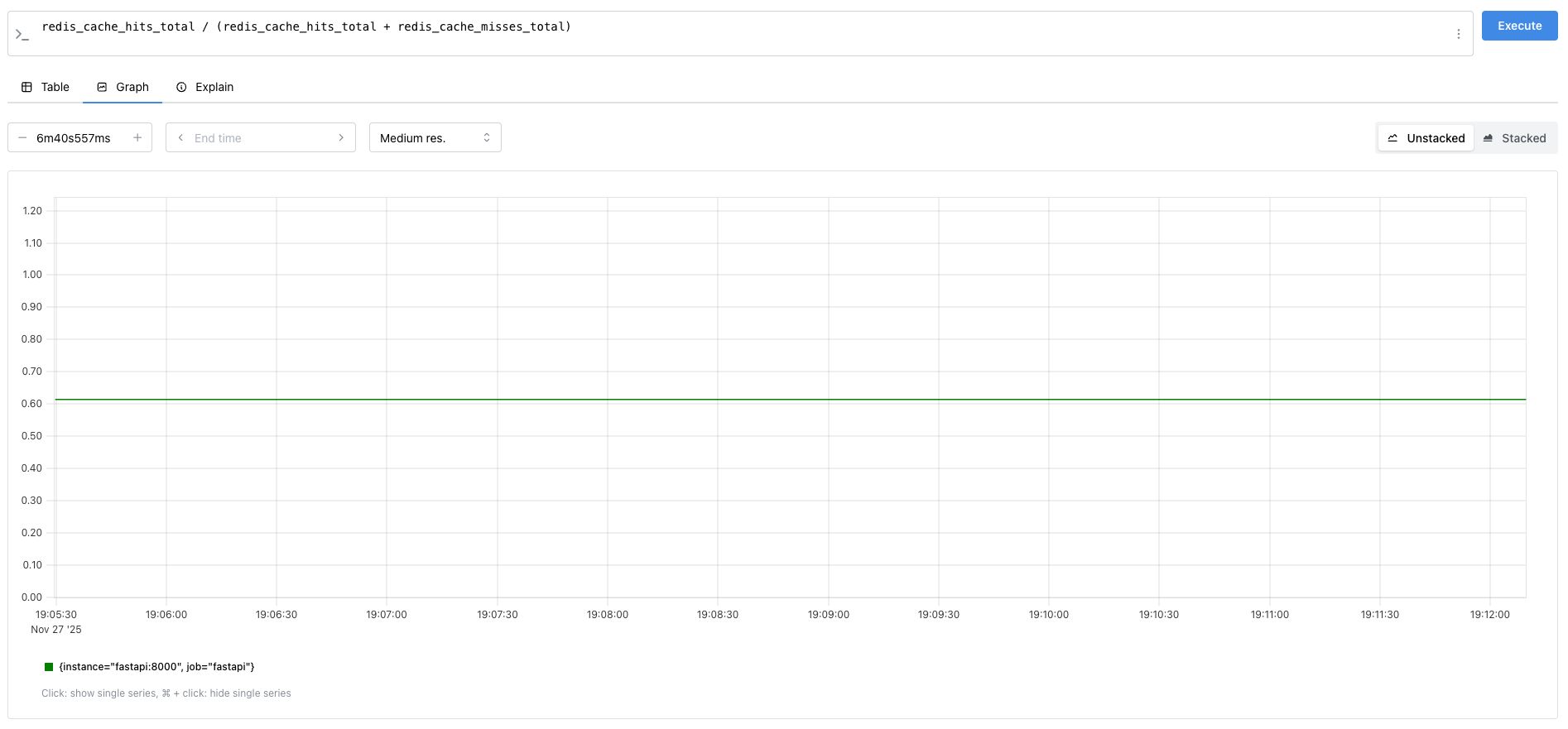
그런데 실제로 나오는 값은 60%를 살짝 웃돈다. 물론 요청 자체가 이상적으로 가지 않았을 확률이 높지만 조금이라도 더 올려보고자 원인을 생각해보면:
- 시퀀싱/동시성 문제 -> 애초에 요청 수 자체가 많기 때문에, 캐시가 비어있는 상황에서 여러 요청이 DB로 치고 들어가고, 다수의 Miss가 발생 (Cache Stampede).
- 잘못된 시나리오 -> 보다 일반적인 Locust 시나리오 구성
우선은 이 두개로 정리해두고, 다음 지표들로 넘어가본다.
요청 성공률 (SLO 체크 핵심)
1
2
3
sum(rate(http_requests_total{status=~"2.."}[1m]))
/
sum(rate(http_requests_total[1m]))
전체 응답 중 2xx 비율을 확인. SLO 99% 확인용.
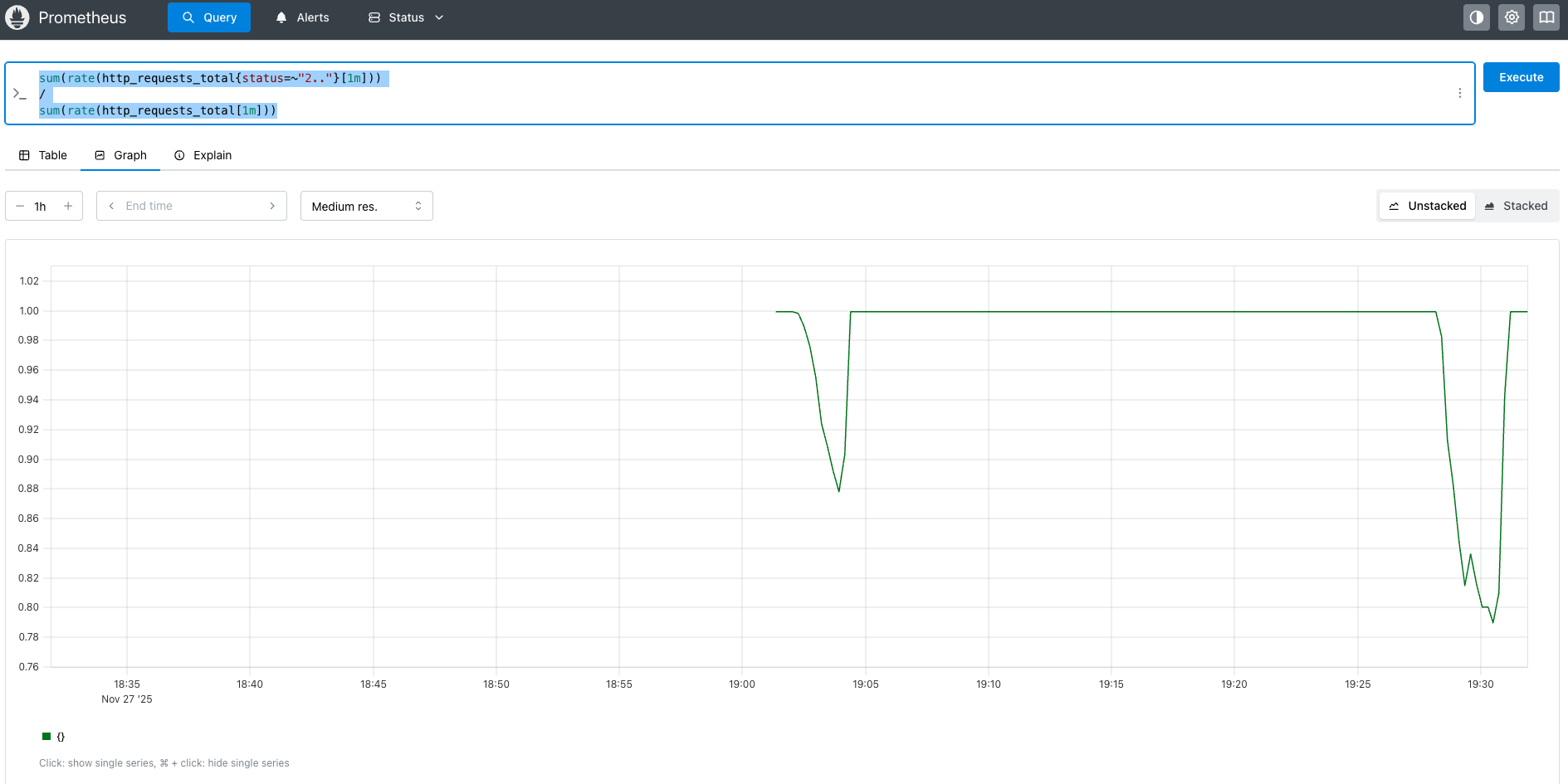
0.99 밑으로 떨어진 구간들이 확실히 보인다. 아무래도, 커넥션 풀 타임아웃 문제기 때문에 한 번 오류가 발생하는 시점에 뭉터기로 발생한다.
커넥션 풀 타임아웃의 원인으로는 다음을 고려해 볼 수 있겠다:
- 쿼리가 느리다 → 커넥션이 오래 잡힌다
- 트래픽이 높다 → pooling 부족
- 커넥션 재사용이 안된다 → 코드 문제
- N+1 문제
1번은 실제로 현재 페이징이 되어있거나, 샤딩과 인덱싱이 이상적으로 적용되어 있지 않기 떄문에 충분히 의심할만 하다.
2번은 사실이지만, 나는 높은 트래픽을 감당하고 싶기 때문에 우선 넘어간다.
3번은 아니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
engine = create_async_engine(
settings.DATABASE_URL,
echo=False,
future=True,
pool_size=20,
max_overflow=20,
)
AsyncSessionLocal = async_sessionmaker(
bind=engine,
class_=AsyncSession,
expire_on_commit=False,
autoflush=False,
)
class Base(DeclarativeBase):
pass
async def get_db() -> AsyncGenerator[AsyncSession, None]:
async with AsyncSessionLocal() as db:
yield db
4번은 실제로 발생 가능성이 있다. 아주 간단한 사용자 - 게시글 - 댓글 구조이지만, 한 번에 모든 게시글을 반환하는 API가 있기 떄문이다. 또한, 하나의 게시글에 대해 모든 댓글을 조회하는 API또한 있다. 다만 스키마에 정의된 Pydantic Model에는 관계 필드가 없기 때문에 발생할지 의문이다.
이쪽을 Eager Loading을 하여 개선해보자:
1
2
3
4
5
6
7
#post_repository.py
async def list(self) -> Sequence[Post]:
stmt = select(Post).options(
selectinload(Post.author), selectinload(Post.comments)
)
result = await self._session.execute(stmt)
return result.scalars().all()
1
2
3
4
5
6
7
8
9
#comment_repository.py
async def list_by_post(self, post_id: int):
stmt = (
Select(Comment)
.where(Comment.post_id == post_id)
.options(selectinload(Comment.author))
)
result = await self._session.execute(stmt)
return result.scalars().all()
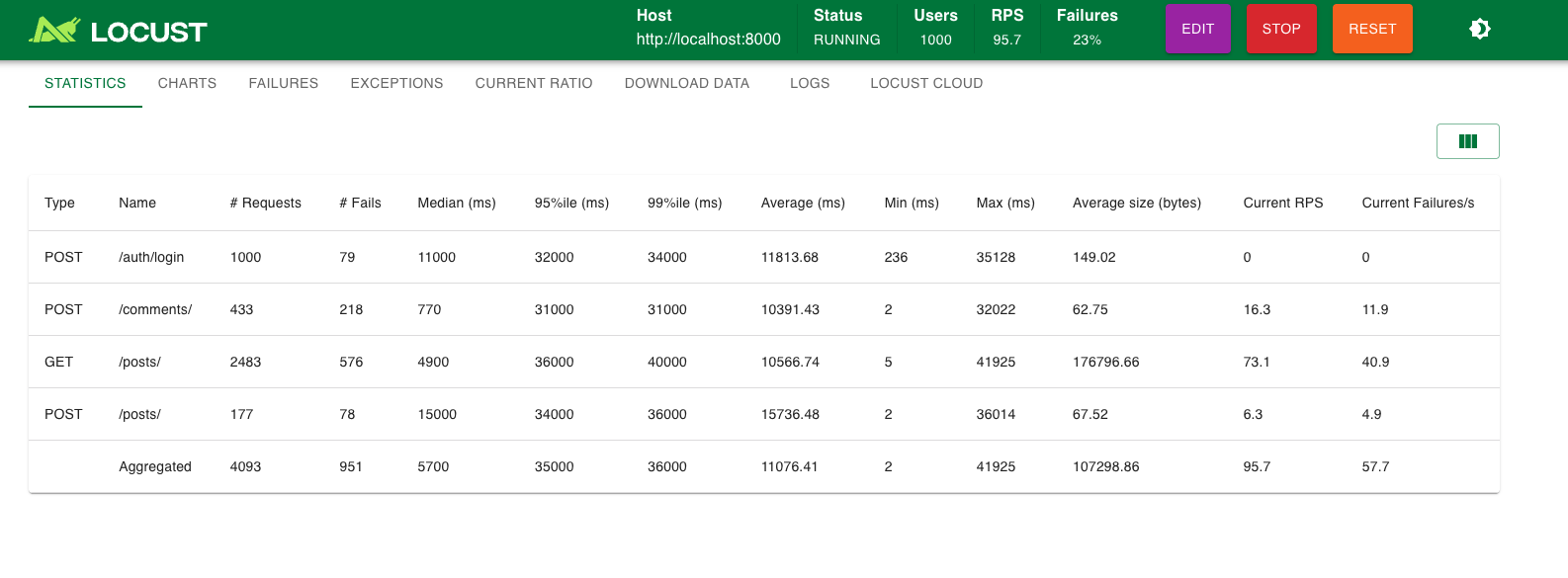
실제로 개선되지 않은 것을 화깅ㄴ할 수 있다.
요청 지연 분포 (p90, p95, p99)
1
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
지난 5분동안의 요청 100개중, 가장 느린 1개가 걸린 시간을 확인하는, p99를 확인하는 PromQL이다.
우선 p99 latency가 높아지면 가장 느린 1% 요청이 병목을 일으키고 있다는 뜻이다.
이는 이미 locust web ui에서 확인한 바 있기 떄문에 특별히 몰랐던 지표는 아니다.
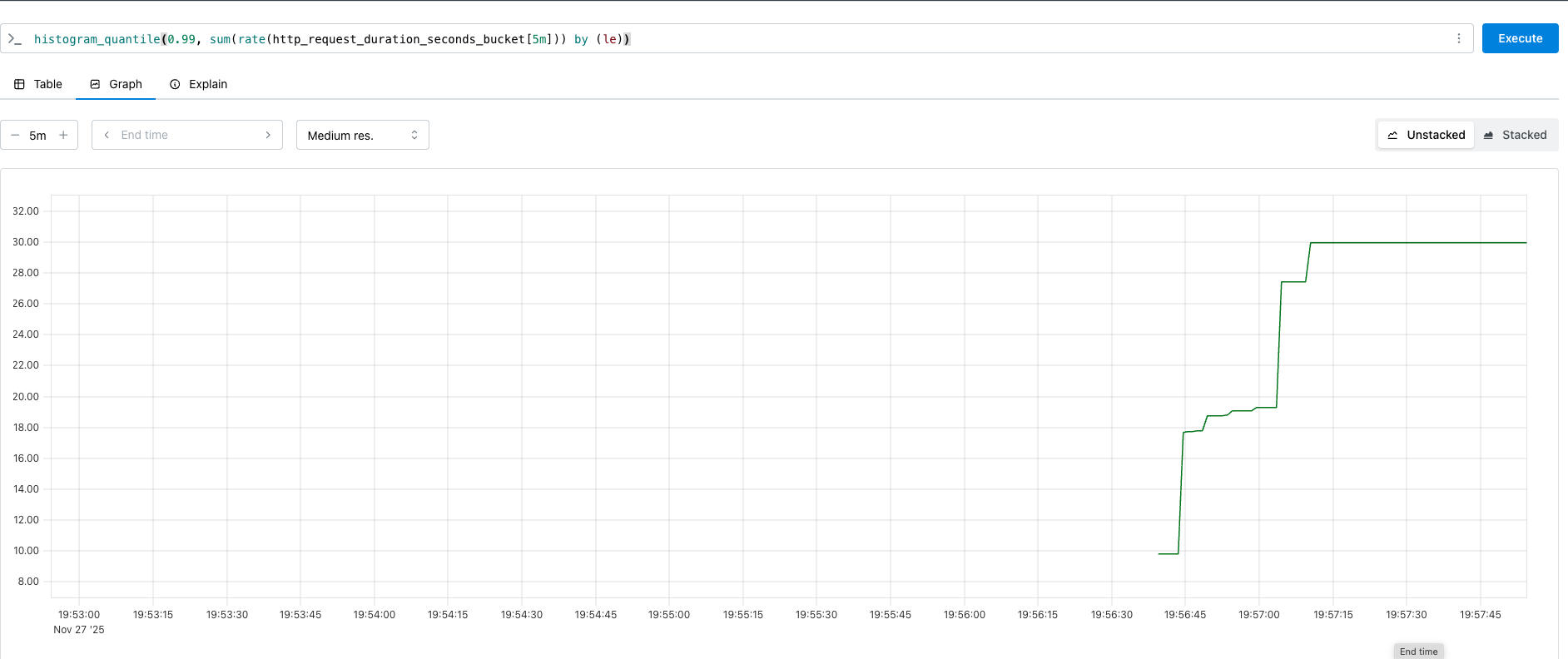
이상적인 p99는 여러 정보를 참조한 결과 400ms로 확인했다. 이게 내가 목표삼아야 할 p99 SLO이다.
컴퓨팅 자원 사용률
서비스를 배포한 이후에는 컴퓨팅 자원 사용율을 node-exporter등으로 측정하는 게 맞지만, 로컬에서 도커에 띄워 서버를 실행할 때는 편리하게도 docker stats cli 커맨드를 사용하면 된다.

CPU는 1.2개정도 사용, 메모리는 200메가를 웃돌고 누수나 병목이 없음.
Net I/O 또한 Locust 부하 테스트라는 것을 감안하면 누적으로 이정도 찍히는 게 정상이다.
즉 서버 자체에는 문제가 없다고 볼 수 있다.