SQLD: 집합 연산자, 그룹 함수, 윈도우 함수
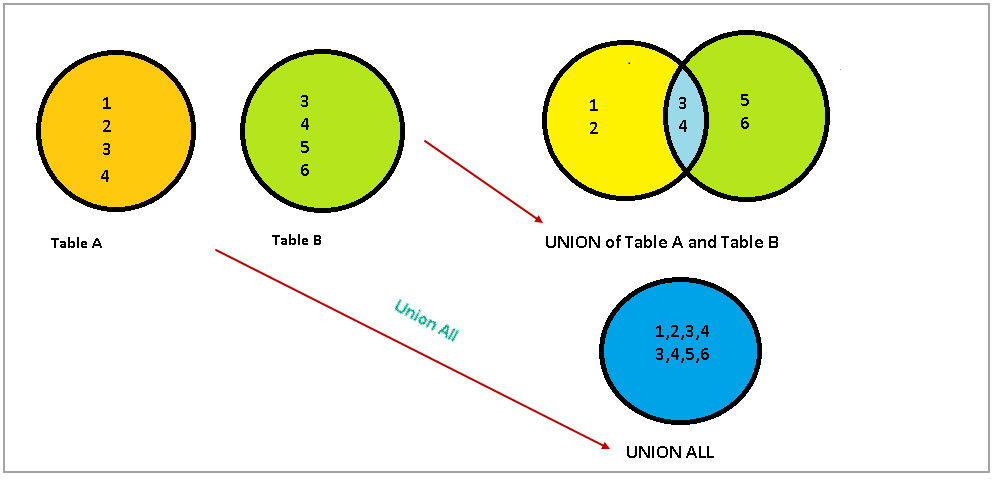
집합 연산자
집합연산자란, 여러 SQL결과를 연결하여 하나의 형태로 결합하는 문법이다.
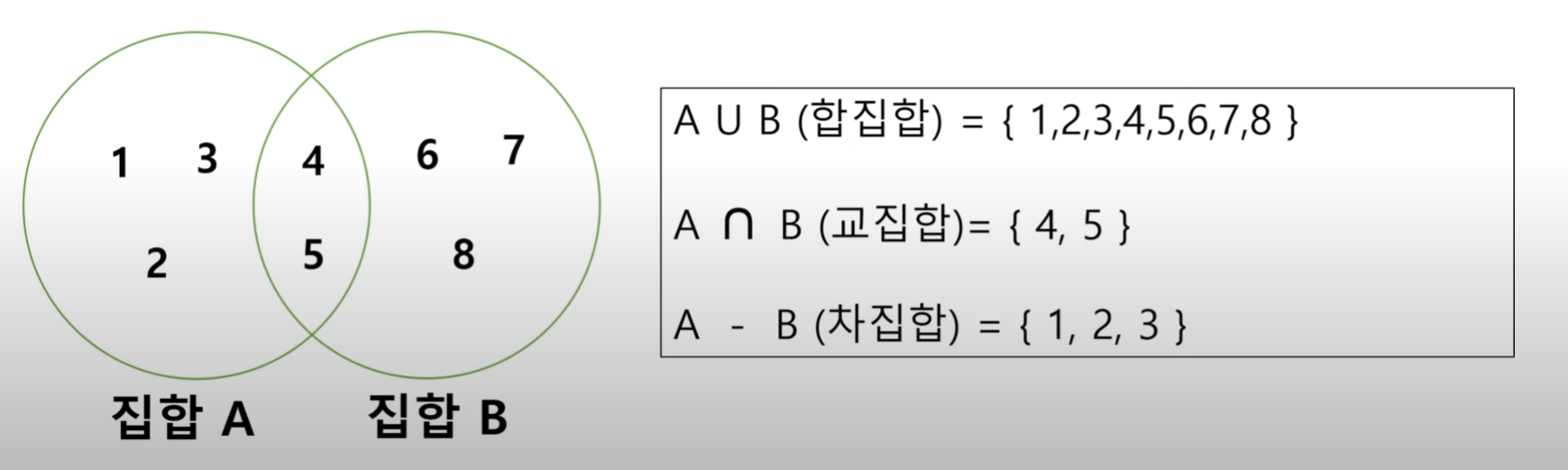
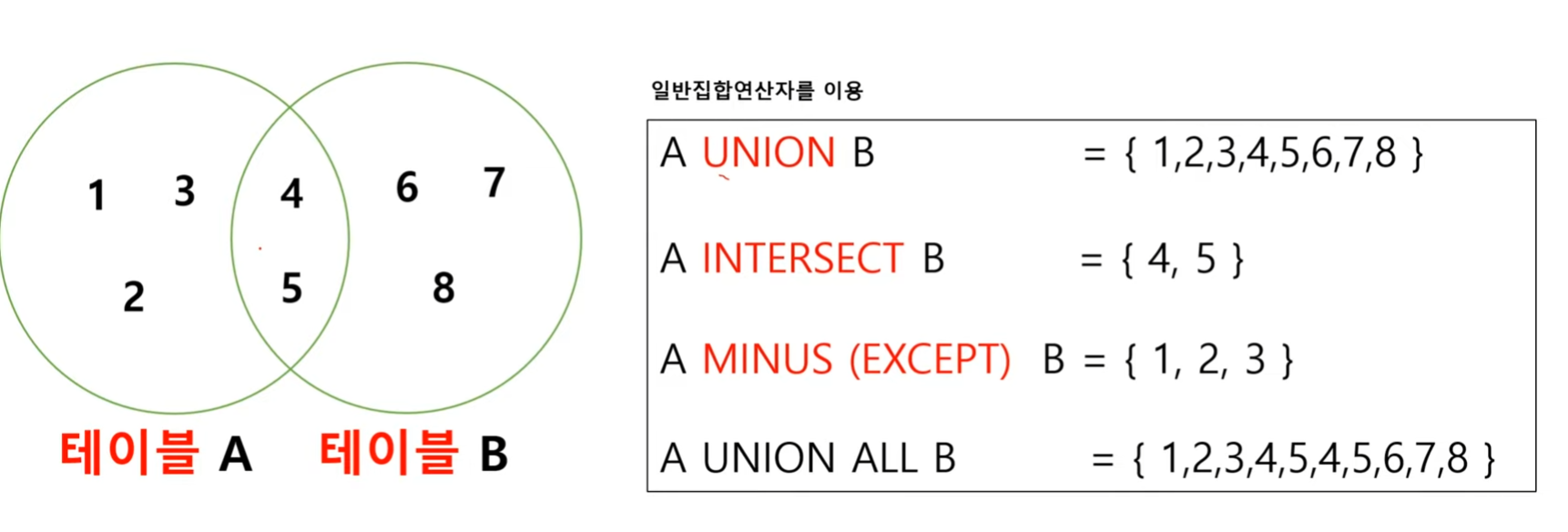
위의 이미지를 아래와 같이 SQL로 변경할 수 있다.
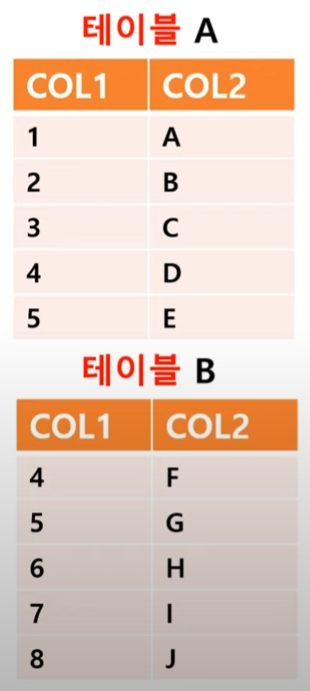
다음의 테이블 A와 B가 있다고 생각해보자:
이에 대해 UNION 연산자와 UNION ALL 연산자를 사용해보겠다.
1
2
3
4
5
SELECT COL1
FROM A
UNION
SELECT COL1
FROM B;
결과: 1,2,3,4,5,6,7,8
UNION은 합집합을 의미한다. 위의 예시에서는, 위 쿼리의 결과와 아래 쿼리의 결과를 합집합 처리하고, 중복을 제거한다 (+정렬).
1
2
3
4
5
SELECT COL1
FROM A
UNION ALL
SELECT COL1
FROM B;
결과: 1,2,3,4,5,4,5,6,7,8
UNION ALL은 UNION과 유사하게 결과를 합집합 처리하지만, 중복을 포함하며 정렬을 하지 않는다.
1
2
3
4
5
SELECT COL1, COL2
FROM A
UNION
SELECT COL1, COL 2
FROM B;
칼럼 여러 개 사용도 가능하며, 이 때는 COL1 + COL2 조합으로 중복을 제거한다.
위 쿼리문과 아래 쿼리문의 컬럼 개수와 형식이 같아야 한다.
INTERSECT는 교집합을 의미한다.
1
2
3
4
5
SELECT COL1
FROM A
INTERSECT
SELECT COL1
FROM B;
결과: 4, 5
INTERSECT는 중복을 제거한다.
MINUS는 차집합을 의미한다.
1
2
3
4
5
SELECT COL1
FROM A
INTERSECT
SELECT COL1
FROM B;
결과: 1, 2, 3
위의 쿼리문의 결과집합에서 아래 쿼리의 결과집합을 차집합하며, 중복을 제거한다.
SQL SERVER에서는 EXCEPT 이다.
집합연산자 ORDER BY 주의사항
집합연산자를 사용할 때 ORDER BY는 항상 마지막에 쓰여야 한다.
위 아래를 합친 결과에 대해서 ORDER BY가 실행된다.
1
2
3
4
5
6
SELECT COL1
FROM B
ORDER BY COL1 --집합연산자를 사용할 때 합치려는 대상의 중간에서 ORDER BY를 쓰지 못한다.
UNION
SELECT COL1
FROM A;
집합연산자 컬럼 이름 주의사항
위쿼리와 아래쿼리의 컬럼 명이 다르다면 위의 컬럼 이름을 따른다.
데이터 유형과 컬럼의 개수는 위와 아래가 일치해야 한다.
집합연산자가 여러개라면?
위에서 아래로 순서대로 풀이하면 된다.
단, 중복 제거에 주의해야 한다.
그룹함수
그룹함수로는 ROLLUP, CUBE, GROUPING SETS가 있다. 이 함수들을 사용하여 다차원 집계를 할 수 있다.
ROLLUP
ROLLUP을 이용하면 소계와 합계를 한번에 추출할 수 있다. 즉, 한번의 작성으로 여러 집계를 낼 수 있다.
1
2
3
SELECT 부서ID, SUM(연봉)
FROM 직원
GROUP BY ROLLUP(부서ID);
GROUP BY ROLLUP(A, B); 는 아래의 쿼리와 같다:
1
2
3
GROUP BY A, B
GROUP BY A
GROUP BY(전체)
CUBE
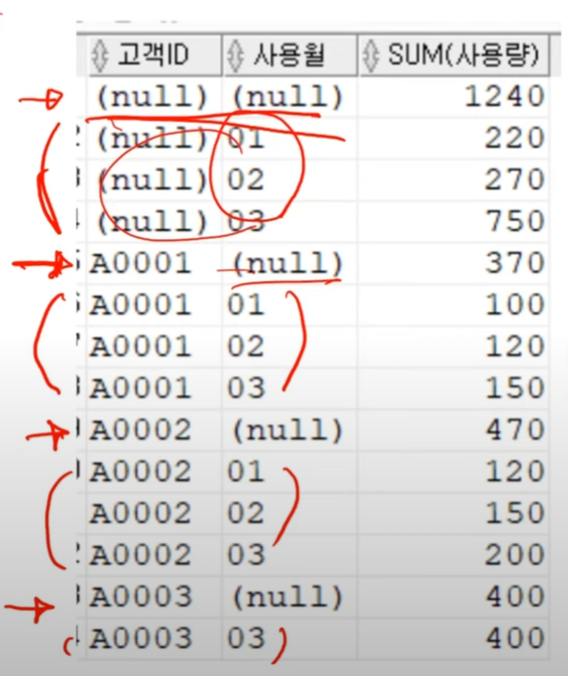
CUBE는 입력된 컬럼의 모든 경우의 수를 집계한다.
1
2
3
SELECT 고객ID, 사용월, SUM(연봉)
FROM 고객월별가스사용량
GROUP BY CUBE(고객ID, 사용월);
GROUPING SETS
입력한 그대로 집계처리를 한다.
1
2
3
SELECT 고객ID, 사용월, SUM(연봉)
FROM 고객월별가스사용량
GROUP BY GROUPING SETS(고객ID, 사용월);
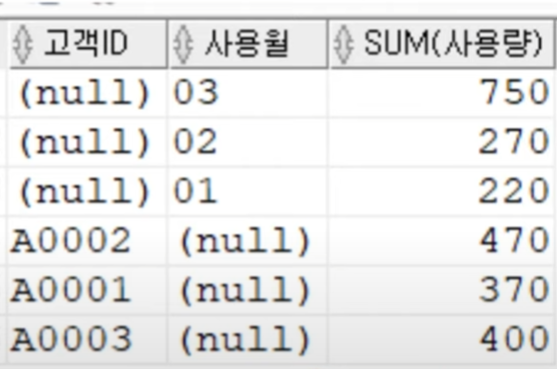
- 전체에 대한 집계가 없다
NULL로 표현되는 부분을 바꿔줄 수 있다: GROUPING()
윈도우 함수
테이블의 행과 행간의 관계를 정의, 비교, 연산할 때 쓸 수 있는 함수 종류
WINDOW_FUNCTION(매개변수) OVER (\PARTITION BY 컬럼]\ORDER BY절]\WINDOWING절])

순위함수
RANK, DENSE_RANK, ROW_NUMBER가 있으며, 이들은 테이블의 행과 행간의 관계를 순위로 비교할 수 있다.
ORDER BY절
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT 지점코드
,(SELECT 지점위치
FROM 지점
WHERE 지점코드 = X.지점코드) AS 지점위치
, 매출액
, RANK() OVER (ORDER BY 매출액 DESC) AS 순위 -- .RANK: 위에서부터 순위를 매겨준다. 같은 값은 동순위를 부여하며, 그 다음 값은 순위를 건너뛴다.
FROM ( --인라인 뷰 - 지점별로 매출액의 합계를 구하는 부분
SELECT A.지점코드
, SUM(B.매출액) AS 매출액
FROM 지점 A INNER JOIN 월별매출 B
ON (A.지점코드 = B.지점코드)
GROUP BY A.지점코드
) X
ORDER BY 순위;
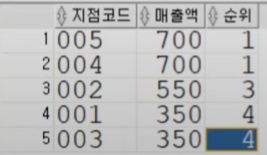
DENSE_RANK: RANK와 동일하나, 순위를 건너뛰지 않는다. 동순위는 여전히 같은 순위를 부여한다.
ROW_NUMBER: 동 순위여도 고유한 순위를 부여한다.
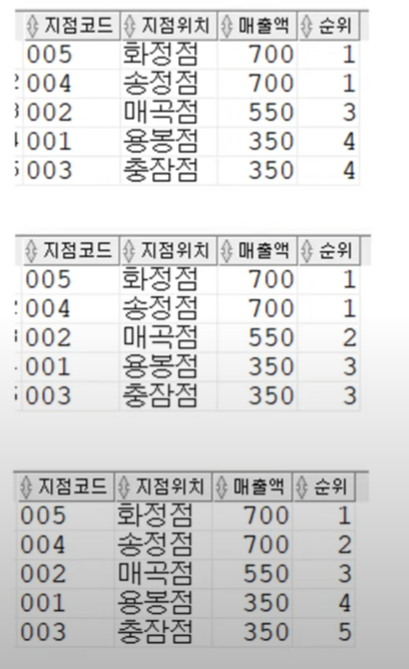
PARTITION BY 컬럼
PARTITION BY: 특정 컬럼의 값을 기준으로 파티션한다.
윈도윙 절
행에 범위를 지정해준다.

위의 문제를 보면, 범위가 UNBOUNDED PRECEDING(이전 처음) AND CURRENT ROW(현재 행)까지로 지정이 되어있으며, 합을 구한다고 한다. 즉, 해당 행까지의 누적합을 구한다는 말이다.
SELECT문에서 조회하기로 한 컬럼은 분류코드, 상품명, 가격, 현재행까지합계 이기 때문에 테이블은 초반 부분은 다음과 같다:
| 분류코드 | 상품명 | 가격 | 현재행가지합계 |
|---|---|---|---|
| 001 | 상품1 | 5000 | 5000 |
| 001 | 상품2 | 8000 | 13000 |
| 001 | 상품3 | 11000 | 24000 |
| 001 | 상품4 | 35000 | 59000 |
| 002 | 상품5 | 25000 | 84000 |
LEAD와 LAG함수
LEAD(컬럼, N, DEFAULT) 함수는 현재 행 기준 N번째 이후 행의 컬럼값을 가져온다.
LAG(컬럼, N, DEFAULT) 함수는 현재 행 기준 N번째 이전 행의 컬럼값을 가져온다.
- 없으면 DEFAULT 값을 가져온다
- N의 기본값은 1