SQLD: PIVOT & UNPIVOT, 정규표현식
PIVOT절과 UNPIVOT절
PIVOT : 행에 있는 데이터를 열로 바꾸기
1
2
3
4
5
6
7
8
9
10
11
SELECT *
FROM (
SELECT 년월, 지점코드, 매출액 -- 사용하려는 컬럼만 명시
FROM 월별매출
)
PIVOT ( -- 행을 열로 바꾸려는 컬럼과 값을 입력
SUM(매출액) FOR 년월 IN ('202201' AS '2022-1') -- 집계처리를 할 컬럼을 입력
,('202202' AS '2022-2')
,('202203' AS '2022-3')
)
ORDER BY 지점코드;
UNPIVOT : 열에 있는 데이터를 행으로 바꾸기
1
2
3
4
5
6
7
SELECT *
FROM PIVOT_TABLE
UNPIVOT ( -- 행을 열로 바꾸려는 컬럼과 값을 입력
매출액 FOR 년월 IN ("2022-1" AS '202201') -- 집계처리를 할 컬럼을 입력
,("2022-2" AS '202202')
,("2022-3" AS '202203')
)
정규표현식
정규표현식이란? (= 패턴화된 표현식)
- 데이터에서 특정 규칙을 가지는 문자열을 찾거나 처리하는데 도움이 되는 고급 쿼리 방법
- 패턴이 특정 형식을 만족하는가? 예: hello@mail.com 혹은 010-1234-5678 처럼 이메일, 휴대폰 패턴이 맞는지 확인 - LIKE의 고급형 (REGEXP_LIKE)
- 패턴에서 특정 문자열을 치환할 때 사용 가능 - REPLACE의 고급형 (REGEXP_REPLACE)
- 패턴에서 특정 문자열을 추출할 때 사용 가능 - SUBSTR의 고급형 (REGEXP_SUBSTR)
- 패턴에서 특정 문자열의 반복개수를 확인할 때 사용 가능 - (REGEXP_COUNT)
- 패턴에서 특정 문자열이 존재하는지 확인 - (REGEXP_INSTR)
정규표현식 와일드카드
. : 모든 문자와 일치 (모든 문자, 문자 1개와 일치)
| : 대체 문자를 구분 (연결연산자 |, OR 개념 [A|B] A 혹은 B)
\ : 특수문자를 이스케이프 처리 (백슬래시)
\d{n} : 숫자를 의미하며, n에 있는 값이 숫자의 개수 - 단순히 \d 면 숫자 한 개
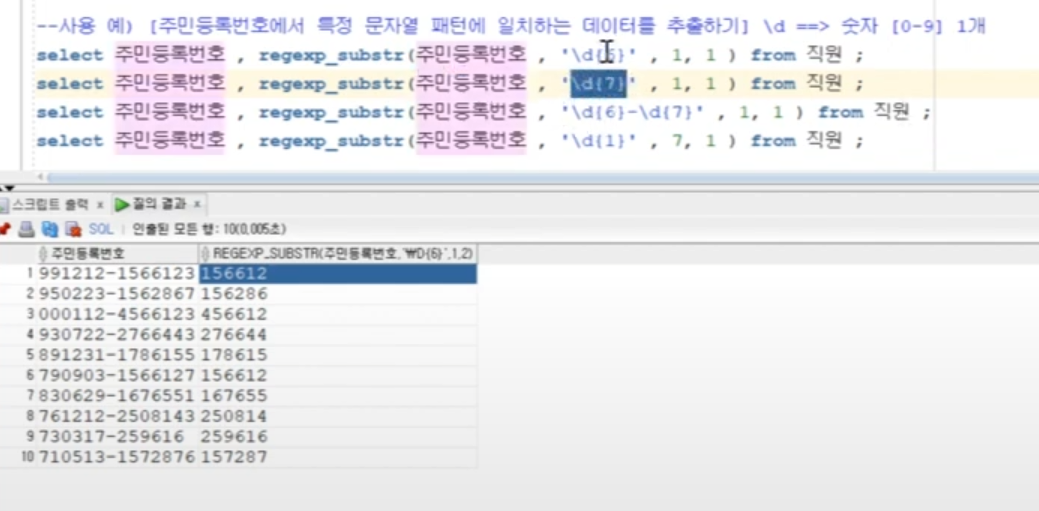
^ : 캐럿 - 문자열의 시작
$ : 문자열의 끝
수량사 - 표현식을 일치하는 횟수 - 탐욕적이다. 즉, 최대한 많이 매칭시킨다.
? : 0~1회 일치
* : 0~무제한 일치
+ : 1~무제한 일치
{m} : m회 일치
{m,} : 최소 m회 일치
{m, n} : 최소 m회 ~ 최대 n회 일치

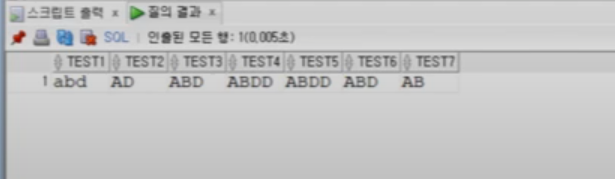
문자리스트를 이용한 표현식:
PERL: [0-9] [a-z] [A-Z] [a-zA-Z] 등
\w : 문자 1개
PERL 방식의 정규표현식 - 비탐욕적이다. 즉, 최소한만을 구한다.
?? : 0~1회 일치
*? : 0~무제한 일치
+? : 1~무제한 일치
{m}? : m회 일치
{m,}? : 최소 m회 일치
{m, n}? : 최소 m회 ~ 최대 n회 일치
REGEXP_LIKE
LIKE처럼 매칭연산을 하며, 정규표현식이 매칭되면 TRUE, 아니면 FALSE를 반환한다.
REGEXP_REPLACE
REGEXP_REPLACE('hello@temp.com', '@.+', '@realdomain.net') AS new_email FROM dual;
@.+를 찾아 @realdomain.net으로 변경하겠다는 말이다.
REGEXP_INSTR
일치하는 패턴의 시작 위치를 반환하며, 매칭값이 없을 시 0을 반환한다.
REGEXP_COUNT
패턴에 일치하는 개수를 확인한다.