SQLD: 정리

시험 팁
SQLD 시험 문제를 풀 때 참고하면 좋을 것들을 정리하고자 만들어봤다.
###
순서 : FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
선택도 : 전체 테이블에서 내가 뽑고자 하는 인스턴스들의 비율
카디널리티(출력된 행의 수) : 선택도 * 전체 레코드 수
CRUD 매트릭스 : INSERT, SELECT, UPDATE, DELETE를 업무 상의 기능, 즉 프로세스의 상관 관계를 매칭한 표
속성
특성
기본 : 업무로부터 추출한 속성
설계 : 코드나 일련번호 등
파생 : 다른 속성으로부터 계산 또는 변형되어 만들어진 속성 (합, 평균 등)
구성방식
PK : 식별자
FK : 빌려온 키 - 외래키
일반속성 : 일반 속성
복합속성 : 물리적으로는 최소단위가 아니지만, 논리적으로는 최소단위 (전화번호, 주소 등)
스키마
외부 : 여러 사용자 각각의 관점
개념 : 통합적, 조직 전체의 데베 관점
내부 : 데이터 물리 저장 구조 표현 - 어떻게 저장할 것인가
정규화
정규화 : 엔터티를 쪼갬으로 데이터의 중복을 제거하여 입력/삭제/수정 성능 향상
반정규화 : 정규화에 따라 조회성능이 떨어질 떄 고려해볼 수 있는 정규화의 역연산
테이블 반정규화 : 테이블을 자주 사용하는 데이터 위주로 쪼개어 특정 컬럼에 대한 중복을 허용하나 조회 성능을 향상
컬럼 반정규화 : 중복컬럼 추가로 조인을 감소시킴
비정규형 : 정규화가 필요한 대상
정규화 과정
-> 도메인원자성(=1차 정규화) : 속성에 대한 속성 값을 하나만 쓰는 것
-> 1NF
-> 부분종속성제거(=2차정규화) : 테이블의 프라이머리 키 (A B)를 사용하고 일반속성 C D E가 있다고 가정할 때, B만으로 D를 식별할 수 있다면(부분적으로 종속한다면) 테이블을 쪼개는 방식 등으로 이를 제거해야 한다.
-> 2NF
-> 이행종속성제거 : 프라이머리 키 (A)가 있고 컬럼 B C D E가 있을 때, 키가 아닌 일반 속성들끼리 종속성이 존재하면 (예: D = 부서코드, E = 부서명) 이를 쪼개준다.
-> 3NF
-> 결정자제거
-> BCNF
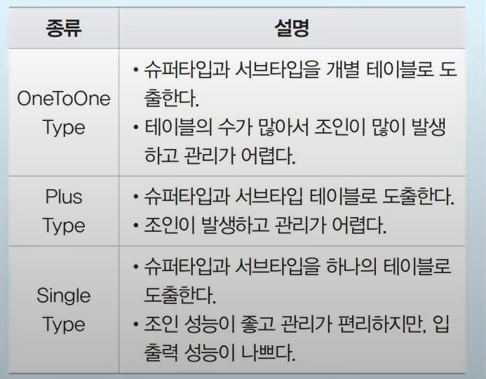
슈퍼/서브타입 데이터 모델
공통적인 특징을 가지는 것은 슈퍼모델로, 각각의 차이는 서브모델로 표현하는 방식
PLUS TYPE : 슈퍼타입과 서브타입 테이블로 도출 - 조인이 발생
SINGLE TYLE : 슈퍼타입과 서브타입을 하나로 모아서 관리하는 방식 - 조회효율이 좋지 않지만 관리가 편함
ONE-TO-ONE : 하나씩 개별로 생성하며 조인이 많이 발생
그룹함수
- ROLLUP : 뒤에서부터 하나씩 제거하면서 그룹화한다
1
2
3
4
5
6
7
GROUP BY ROLLUP (A, B)
-- 위 아래 동일
GROUP BY (A, B)
GROUP BY (A)
GROUP BY ()
- CUBE : 조합이 가능한 모든 경우의 수 (2^N승, N은 컬럼의 수)
1
2
3
4
5
6
7
8
GROUP BY CUBE (A, B)
-- 위 아래 동일
GROUP BY (A, B)
GROUP BY (A)
GROUP BY (B)
GROUP BY ()
- GROUPING SETS : 순차적으로 하나씩 그루핑
1
2
3
4
5
6
GROUP BY GROUPING SETS (A, B)
-- 위 아래 동일
GROUP BY (A)
GROUP BY (B)
TCL
- COMMIT
- ROLLBACK
- SAVEPOINT
DDL
변경할 때 MODIFY를 쓴다 (SQL Server 는 ALTER COLUMN)
- CREATE
- ALTER
- DROP
- RENAME
집합연산자
UNION : 합집합, 중복 제거, 정렬
UNION ALL : 합집합, 중복 허용, 정렬 X
INTERSECT : 교집합
MINUS : 차집합
계층형 쿼리
CONNECT BY : 전개조건
PRIOR : 기준점 - PRIOR 자식이면 순방향
CONNECT_BY_ISLEAF : 단말이면 1, 아니면 0 (IS 참고!)
윈도우 함수
OVER가 있으면 윈도우함수
- RANK : 같은 값이 있으면 같은 순위를 매기고, 같은 순위만큼 건너뜀
- DENSE_RANK : 위와 같으나 건너뛰지 않음
- ROW_NUMBER : 같은 순위 안주고 123456..순서로 매김
범위: RANGE BETWEEN ~
PRECEDING : 이전
FOLLOWING : 이후
UNBOUNDED : 범위 제한 없음
CURRENT : 지금 행까지의
PARTITION이 있다면 해당 파티션 내까지만 범위로 한정짓는다.
키

파티션
Range : 범위에 대한 파티션
List : 파티션 범위를 직접 지정
Hash : 조건 X, 임의의 값을 주면 저장할 곳을 알아서 정의
Composite/Hybrid : 위를 조합하여 지정
조인
- 카티션 조인 : 단순히
FROM A, B식으로 테이블 두 개를 기재. 결과는 전체 가능한 조합을 나타내며, A 테이블의 행 수 * B 테이블의 행 수로 결과가 나온다. ANSI에서는CROSS JOIN이며 ON 조건이 붙을 수 없다. - 이너 조인 :
FROM A, B에다가WHERE A.D = B.C라는 조건이 있다면 이너 조인이다. ANSI 방식에서는FROM A INNER JOIN B에 WHERE 조건이ON (A.D = B.C)라는 조건으로 붙는다. 추가적인 AND로 조건이 붙는다면 이것이 WHERE로 붙는다. - 아우터 조인:
FROM A, B WHERE A.D = B.C(+)등의 (+)기호가 붙으면 아우터 조인이다. ANSI 방식에서는FROM A LEFT OUTER JOIN과 같이 (+)의 반대편을 가리킨다.FULL OUTER JOIN도 있는데, 이는 양쪽 테이블 모두 아우터 조인 하는 것이며 오라클 문법에서는 존재하지 않는다.
서브쿼리
- 스칼라 서브쿼리 : SELECT에서 사용하는 서브쿼리 - 하나의 행과 하나의 컬럼이 결과로 나와야 한다. SELECT문에서 나오는 행의 개수만큼 실행되고, 하나의 투플에 하나의 컬럼으로 값을 찾는 것이기 때문에 당연히 하나의 값만 넣어져야 한다는 것이다.
아우터 조인으로 변경이 가능하다. - 인라인 뷰 : 별도로 실행하여 테이블을 만들 수 있으며, 이를 조인할 수 있다.
- 중첩서브쿼리 : 상관과 비상관으로 나뉘며, 이는 메인쿼리와 관계가 있는지에 따라 달라진다. (메인쿼리의 컬럼이 있느냐 없느냐) 상관일 경우 메인쿼리가 먼저 실행되며, 비상관일 경우 서브쿼르를 먼저 실행해도 된다.
WHERE절에서 서브쿼리 결과를 받을 때는 단일행이 될 수 있으며 다중행이 될 수도 있다. 이 때 받을 수 있는 연산자가 나뉜다.