CS & 알고리즘 스터디: 다섯 번째 스터디
다섯 번째 스터디
어느 새 다섯 번째 스터디이다. 이제 뭔가 일주일의 루틴이 된 느낌이라 흘러가는 듯 하는 것 같다. 익숙해질 법도 한데, 그만큼 내가 별도로 매주 하려는 것도 더 늘어나서 그런지 공부 부담이 갈수록 커져가는 게 느껴진다. 스터디와 별개로 현재 SQLD, AWS Solutions Architect, 컴퓨터 관련 독서 모임, 사이드 프로젝트 등을 진행하고 있는데, 이게 맞는건가 의심이 든다. 한두개에 집중을 해야 하는건지, 아니면 더 오랜 장기 기억화를 위해 현재의 방법이 맞는건지 늘 고민이 든다. 다만 개인적으로 느끼는 피로도로 인해 능률이 떨어지는 것 같으니 다음 주에는 적절한 휴식을 취해주는 게 중요할 것 같다.
다행히도 지금 남아 있는 스터디원들은 현재의 스터디에 꽤나 만족하고 있어 보여 괜히 뿌듯하다. 3주차부터 이어진 질문(모의 면접) 형태로 진행 이어가고 있는데 이게 생각보다 꽤 효과적이다. 기억에도 더 잘 남고, 괜히 긴장되는 것도 진짜로 실전 면접을 대비하는 것 같아 좋다.
키워드
IPC
Q: IPC가 무엇이고, 어떤 종류가 있는지 설명해 주세요.
A:
IPC는 Inter-Process Communication, 즉 프로세스 간 통신의 약자로 프로세스들이 서로 데이터를 교환하거나 상호 작용할 수 있도록 하는 메커니즘이다.
IPC에는 다양한 종류가 있다:
- 파이프
- 익명 파이프: 부모-자식 프로세스 간 통신을 위해 보통 사용되는 단방향 통신 메커니즘
- 명명된 파이프: 서로 관련 없는 프로세스 간 통신을 위해 사용되는 양방향 통신 파이프
- 메시지 큐
- 큐 형태로 저장되는 메시지로 프로세스 간 비동기식 통신 허용
- 프로세스 A가 메시지 큐에 메시지를 넣고, 프로세스 B가 큐에서 이를 꺼내서 처리 - FIFO
- 공유 메모리
- 여러 프로세스가 동일한 메모리 공간을 공유하며 데이터 교환
- 가장 빠르며, 동기화 문제를 해결하기 위해 세마포어와 함께 사용
- 세마포어
- 프로세스 간의 접근을 제어하기 위한 동기화 도구
- 소켓
- 네트워크 프로그래밍에서 원격 프로세스 간 통신 허용
- TCP/IP 또는 UDP 프로토콜을 사용하여 통신
- 시그널
- 프로세스에 대한 이벤트 발생을 알리는 신호 전송
Q: Shared Memory가 무엇이며, 사용할 때 유의해야 할 점에 대해 설명해 주세요.
A:
Shared Memory(공유 메모리)는 여러 프로세스가 동일한 메모리 공간을 공유하여 데이터를 교환하는 IPC 메커니즘이다.
공유 메모리 특징:
- 속도: 메모리 자체를 공유하기 때문에 가장 빠른 IPC 메커니즘 중 하나이다.
- 직접 접근: 프로세스는 공유 메모리 영역을 직접 읽고 쓸 수 있다.
- 버퍼링 없음: 데이터가 직접 메모리에 쓰여지고 읽혀지기 떄문에 버퍼링 지연이 없다.
- 공간 공유: 여러 프로세스가 동일한 메모리 공간에 접근할 수 있기 때문에 대용량 전송에 효과적이다.
공유 메모리를 사용할 때는 동기화 문제에 유의해야 한다. 여러 프로세스가 동시에 동일한 공간의 메모리에 접근하기 때문에 경쟁 상태가 발생할 수 있다. 이를 방지하기 위해 세마포어 또는 뮤텍스 등의 동기화 메커니즘과 함께 쓰는 것이 권장된다. 또한, 여러 프로세스가 공유 메모리에 접근하기에 민감한 데이터를 다룰 때는 주의해야한다.
캐시 메모리
Q: 캐시 메모리는 어디에 위치해 있나요?
A:
캐시 메모리는 컴퓨터 시스템 측면에서 보았을 때 주메모리(RAM)과 CPU 사이에 위치하며, 데이터 접근 속도를 높이기 위해 사용된다.
Q: L1, L2 캐시에 대해 설명해 주세요.
A:
우선 L1와 L2란 캐시 메모리의 ‘레벨’로 나눈 호칭이다. 캐시의 용량과 성능이 증가함에 따라 캐시의 캐시로 사용되는 메모리가 ‘멀티 레벨 캐시 메모리’라는 구조로 추가되었는데, 이 중 가장 고성능의 메모리를 L1캐시라고 명명했다. L2, L3,… 캐시 또한 있는데, 숫자가 증가함에 따라 성능은 더 느려지되 용량이 더 커진다. 캐시의 역할 중 하나는 아주 빠른 레지스터와 느린 주메모리 사이의 성능 차이를 줄이는 것이며, 메모리 접근 속도의 병목 현상을 줄여준다.
Q: 캐시의 지역성을 기반으로, 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이에 대해 설명해 주세요.
A:
캐시의 지역성 원리에는 시간 지역성과 공간 지역성이 있다.
시간 지역성
최근에 사용된 데이터는 가까운 미래에 다시 사용될 가능성이 높다.
공간 지역성
인접한 메모리 위치의 데이터는 함께 접근될 가능성이 높다.
이차원 배열 탐색 방향에 따라서 성능의 차이는 다음과 같다:
- 행 우선 순서로 탐색:
- 높은 공간 지역성
- 효율적인 캐시 사용
- 열 우선 순서로 탐색:
- 낮은 공간 지역성
- 비효율적인 캐시 사용
이에 따라 행 우선 순서로 탐색하는 것이 보다 효율적이다.
메모리 연속할당
Q: first fit, best fit, worst fit에 대해 설명해주세요
A:
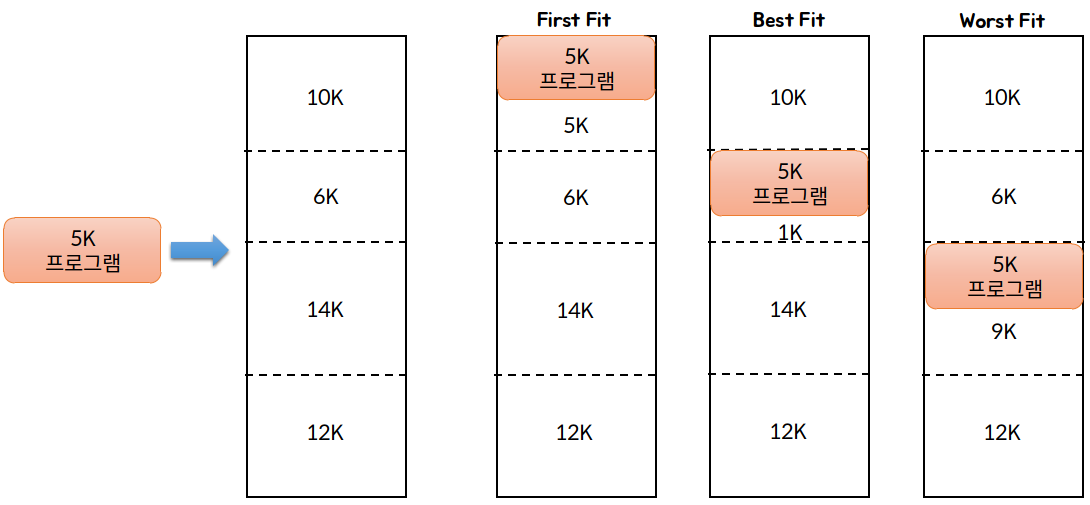
First-Fit: 빈 공간 리스트의 메모리를 주소순으로 유지하며, 할당속도를 빠르게 할 수 있는 방법으로, 프로세스가 적재될 수 있는 빈 공간 중에서 가장 먼저 발견되는 곳을 할당한다.
Best-Fit: 추후 할당해야할 큰 프로세스를 위해 큰 빈 공간들을 최대한 많이 남겨 놓기 위한 방법으로, 현재 할당할 수 있는 빈 공간 중 가장 작은 곳을 선택하여 할당한다.
Worst-Fit: Best-fit과는 반대되는 개념으로, 현재 남은 빈 공간 중 가장 큰 곳을 선택하여 할당한다.
Q: worst-fit 은 언제 사용할 수 있을까요?
Best-fit의 설명을 읽으면 worst-fit을 왜 사용해야 하는가에 대한 의문이 생길 수 있다. Worst-fit의 주요 목적은 작은 자투리가 남지 않게 하는 것이다. Best-fit은 큰 메모리 공간을 아껴두지만, 어떠한 프로세스도 사용하지 못하는 작은 자투리 공간을 남겨두기에 단편화가 일어난다. 반면, worst-fit 알고리즘은 큰 블록에 할당함으로 사용이 어려운 작은 조각들이 생기는 것을 방지할 수 있다.
Q: 성능이 가장 좋은 할당 알고리즘은 무엇일까요?
할당 알고리즘의 성능은 요구된 상황에 따라 다르다고 볼 수 있다.
빠른 탐색과 할당에 중점을 둔다면 first-fit 또는 next-fit이 가장 성능이 좋은 알고리즘일 것이며, 단편화 관련 최적화 측면에서 본다면 worst-fit이나 best-fit이 가장 좋을 수 있다.
가상 메모리
Q: 가상 메모리란 무엇일까요?
A:
가상 메모리란 컴퓨터 시스템에서 물리 메모리와 보조 기억장치를 조합하여 더 큰 메모리를 사용하는 것처럼 보이도록 하는 메모리 관리 기법이다.
Q: Page Fault가 발생했을 때, 어떻게 처리하는지 설명해 주세요.
A:
페이지 폴트는 프로세스가 접근하려는 페이지가 현재 물리 메모리에 적재되어 있지 않은 경우 발생한다. 이 때 운영체제는 페이지 테이블을 참조하여 디스크에서 물리 메모리로 해당 페이지를 로드하며, 프로세스의 주소 공간을 업데이트한다.
Q: 페이지 크기에 대한 Trade-Off를 설명해 주세요.
A:
- 큰 페이지 크기:
- 한 개의 페이지에 더 많은 데이터를 포함하기 떄문에 캐시에서 더 많은 연속된 데이터를 한 번에 로드할 수 있다. 공간 지역성을 더 활용할 수 있으며, 한 번의 페이지 폴트에 더 많은 데이터를 로드할 수 있다. 다만, 내부 단편화에 취약하며 이는 곧 메모리 낭비로 이어진다.
- 작은 페이지 크기:
- 내부 단편화를 줄여주지만, 잦은 페이지 폴트가 발생할 수 있다. 한 개의 페이지에 로드되는 데이터가 상대적으로 적기 떄문에 잦은 페이지 폴트와 데이터 교체로 인해 성능이 저하될 수 있다.
Q: 페이지 크기가 커지면, 페이지 폴트가 더 많이 발생한다고 할 수 있나요?
A:
아니다. 큰 페이지에는 한 번의 페이지 폴트로 더 많은 데이터를 메모리에 로드할 수 있기 때문에 단일 페이지 폴트의 효율이 높아질 수 있다.
Q: 세그멘테이션 방식을 사용하고 있다면, 가상 메모리를 사용할 수 없을까요?
A:
세그멘테이션 방식을 사용해도 가상 메모리를 사용할 수 있다. 세그멘테이션은 논리적 단위로 메모리를 나누는 기법이기에 크기는 고정되어 있지 않으며, 적용된 프로그램의 논리적 구조를 반영한다. 이를 가상 메모리 기법과 함께 사용하면 세그먼트로 나누어진 메모리를 다시 한 번 페이지 단위로 나누어 관리할 수 있다.
문제 풀이
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import sys
input = sys.stdin.readline
def binary_search(arr, key):
lt = 1
rt = max(arr)
longest = 1
while lt <= rt:
mid = (lt + rt)//2
amnt = 0
for elem in arr:
amnt += elem//mid
if amnt >= key:
longest = max(longest, mid)
lt = mid + 1
else:
rt = mid - 1
return longest
if __name__ == "__main__":
K, N = map(int, input().split())
lan = list()
for _ in range(K):
lan.append(int(input()))
ans = binary_search(lan, N)
print(ans)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**8)
def dp(num, arr):
if cache[num] != 0:
return cache[num]
if num == 1 or num ==2 or num == 3:
return num
cache[num] = dp(num-3, cache) + (num//2 + 1)
return cache[num]
if __name__ == "__main__":
T = int(input())
for _ in range(T):
n = int(input())
cache = [0]*10001
print(dp(n, cache))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import sys
input = sys.stdin.readline
def dfs(start, arr):
stk = []
stk.append(start)
path = []
added = set()
while stk:
now = stk.pop()
if visited[now] == 0:
visited[now] = 1
path.append(now)
for node in arr[now]:
if visited[node] == 0:
stk.append(node)
added.add(node)
elif node in path:
return path
for node in path:
visited[node] = 0
N = int(input())
adj = [[] for _ in range(N+1)]
visited = [0] * (N+1)
result = []
for i in range(1, N+1):
num = int(input())
adj[i].append(num)
for i in range(1, N+1):
if visited[i] == 0:
print("next path", i, sep=" ")
local = dfs(i, adj)
print(local)
if local:
result += local
result.sort()
result = set(result)
print(len(result))
list(map(print, result))
누가 설명해줬으면 좋겠다…위는 미완성 코드이다.